
一、前言
笔者由于某种机缘接触了一下hadoop,觉得hadoop还是有所说道的,今天也算是经过不小的折腾才算是搭建好了一个三个节点的hadoop集群。也算是自己走过的坑的总结吧,下面就说说如何搭建hadoop集群。
二、搭建基础
我是在VMware+CentOS下实现的,另外用XShell实现对虚拟机的操作。
三、搭建步骤
1.利用XShell rz命令从本机导入jdk压缩包,然后在usr下解压。
2.编辑profile文件,vim /etc/profile 在后面添加如下内容:(测试命令:java -version)
JAVA_HOME=/usr/java1.8.0
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
在配置文件编辑完成后,source /etc/profile 重新加载一下
注:java1.8.0为你解压后的文件夹名,/usr为解压路径,即解压后文件夹路径
你可以所有的都配好了在克隆,但我选择的是配置好jdk后就克隆,在配置其他的,然后再用scp命令拷贝到其他结点上。
3.克隆,以你第一个操作的主机位基础克隆另外两台机器。在VMware中选中主机,右键–>管理–>克隆。
在克隆时,注意文件夹位置,以及名称,按一般的规则来~01,~02之类的,同时要选择完全克隆的选项,之后默默等待就好了。
注意:克隆时要关闭主机的电源
4.修改主机名:使名称与各机器对应
hostnamectl set-hostname newname
5.利用XShell rz上传并解压hadoop-2.7.5压缩文件,同样是在/usr下
6.编辑profile vim /etc/profile 在后面添加如下内容:(测试命令:hadoop)
HADOOP_HOME=/usr/hadoop-2.7.5
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_HOME PATH
然后 soure /etc/profile 重新加载下 ,在测试
7.添加内网域名映射:为了用主机名访问,方便操作。
vim /etc/hosts
添加如下内容:
192.168.122.134 master
192.168.122.135 master2
192.168.122.136 master3
然后,其他两台也要改成这样,可以直接去改,但为了方便我们可以使用scp命令
scp /etc/hosts root@master2:/etc/
scp /etc/hosts root@master3:/etc/
8.配置免密登陆:
在root路径下,键入命令 ssh-keygen,一路回车,然后
ssh-copy-id master
ssh-copy-id master2
ssh-copy-id master3
其他两台也要这样操作
注意:免密码登陆并不是不要密码,是通过密钥先获取密码,然后用密码和用户名再次请求登陆
9.修改hadoop-env.sh把里面的JAVA_HOME改成,JAVA_HOME=/usr/jdk1.8.0
10.修改 /usr/hadoop-2.7.5/etc/hadoop/core-site.xml,即修改core-site.xml,添加如下内容
注意:主机名要和自己配的一致1
2
3
4
5
6
7
8
9
10
11
12<configuration>
<!-- 指定HDFS(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.5/temp</value>
</property>
</configuration>
11.修改 /usr/hadoop-2.7.5/etc/hadoop/hdfs-site.xml
注意:主机名要和自己配的一致1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 <configuration>
<!-- 设置namenode的http通讯地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 设置secondarynamenode的http通讯地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master2:50090</value>
</property>
<!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.7.5/hdfs/name</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-2.7.5/hdfs/data</value>
</property>
</configuration>
12.修改 /usr/hadoop-2.7.5/etc/hadoop/slaves
注意:主机名要和自己配的一致,覆盖该文件中的localhost1
2
3master
master2
master3
13.分发配置好的hadoop-2.7.5
scp /usr/hadoop-2.7.5 root@master2:/usr/
scp /usr/hadoop-2.7.5 root@master3:/usr/
14.别忘了分发配置好的/etc/profile
scp /etc/profile root@master2:/etc/
scp /etc/profile root@master3:/etc/
然后再在每台机器中 source /etc/profile 重新加载下配置文件
15.执行命令 hadoop namenode -format,在HDFS主节点上执行命令进行初始化namenode
16.启动集群,start-dfs.sh
17.测试每台机器 输入 jps1
2
3
4
5
6
7
8
9
10
11
12
13master:
5458 DataNode
5908 Jps
5352 NameNode
master2:
9975 SecondaryNameNode
8986 DataNode
16670 Jps
master3:
9367 DataNode
20265 Jps
18.去网页上输入http://master:50070进行测试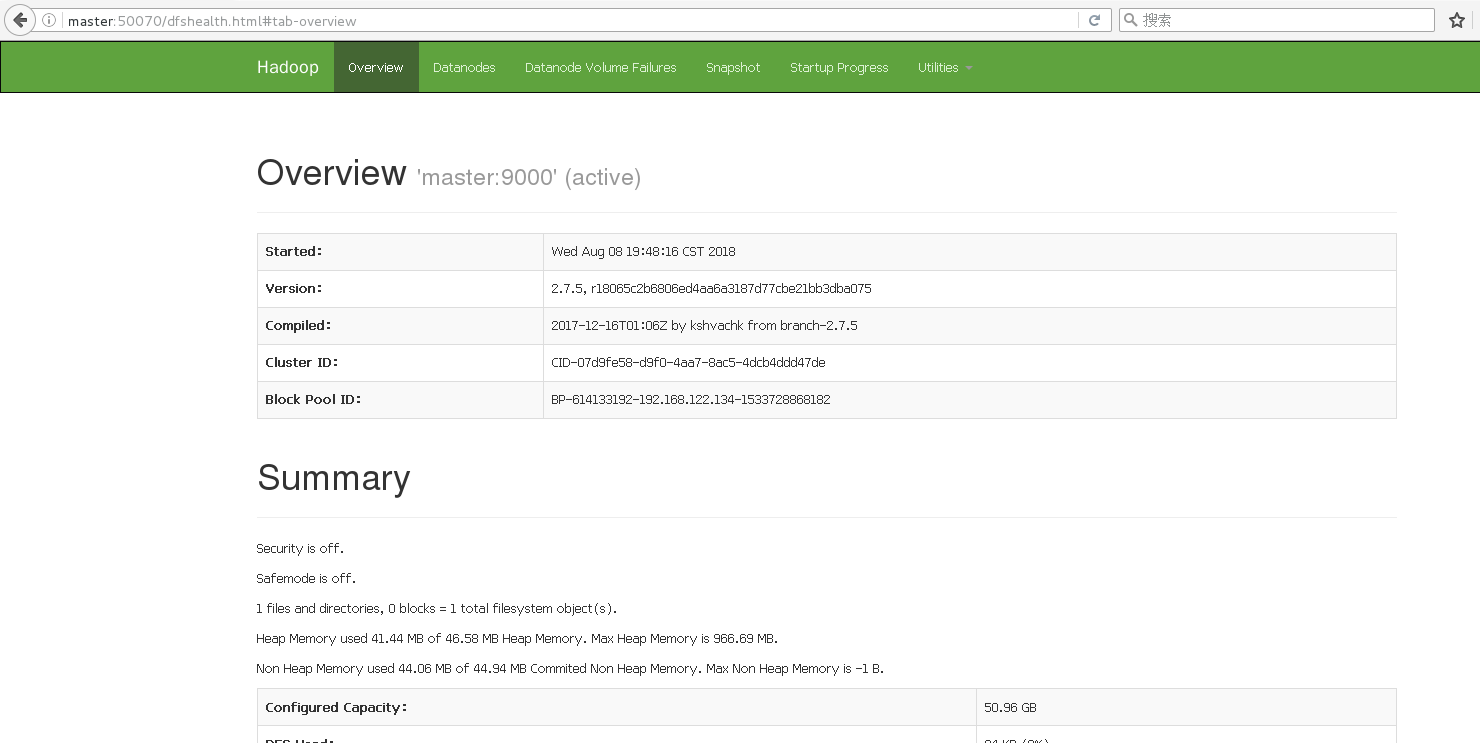
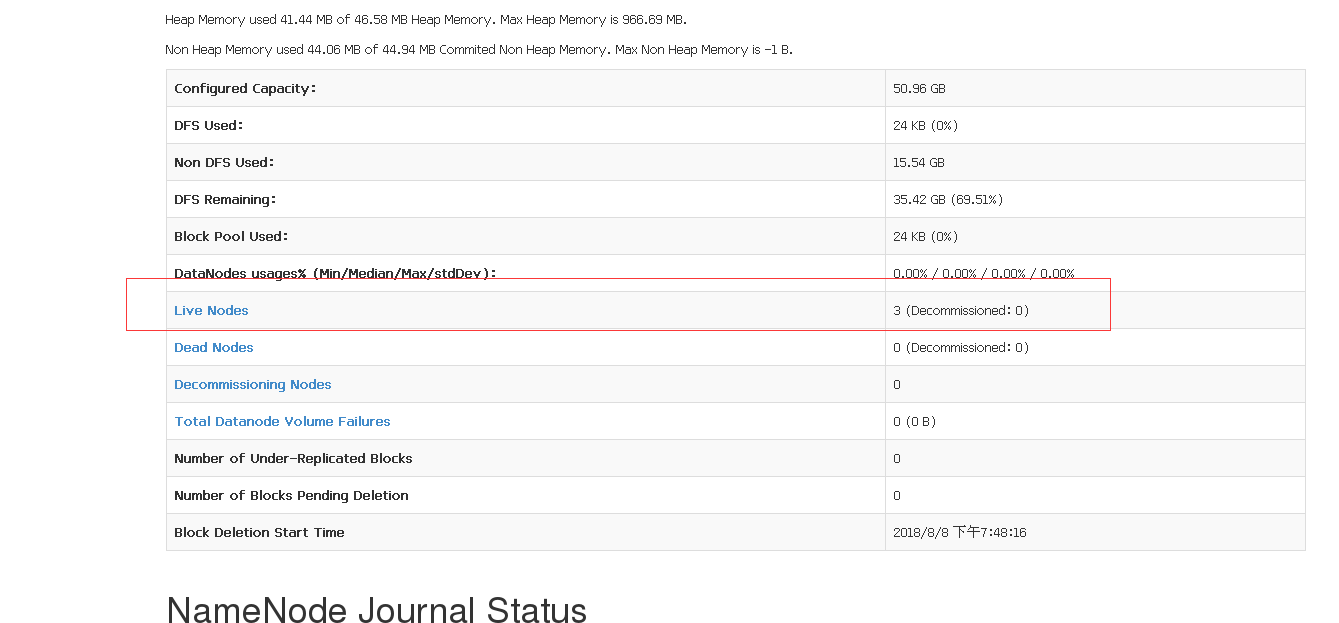
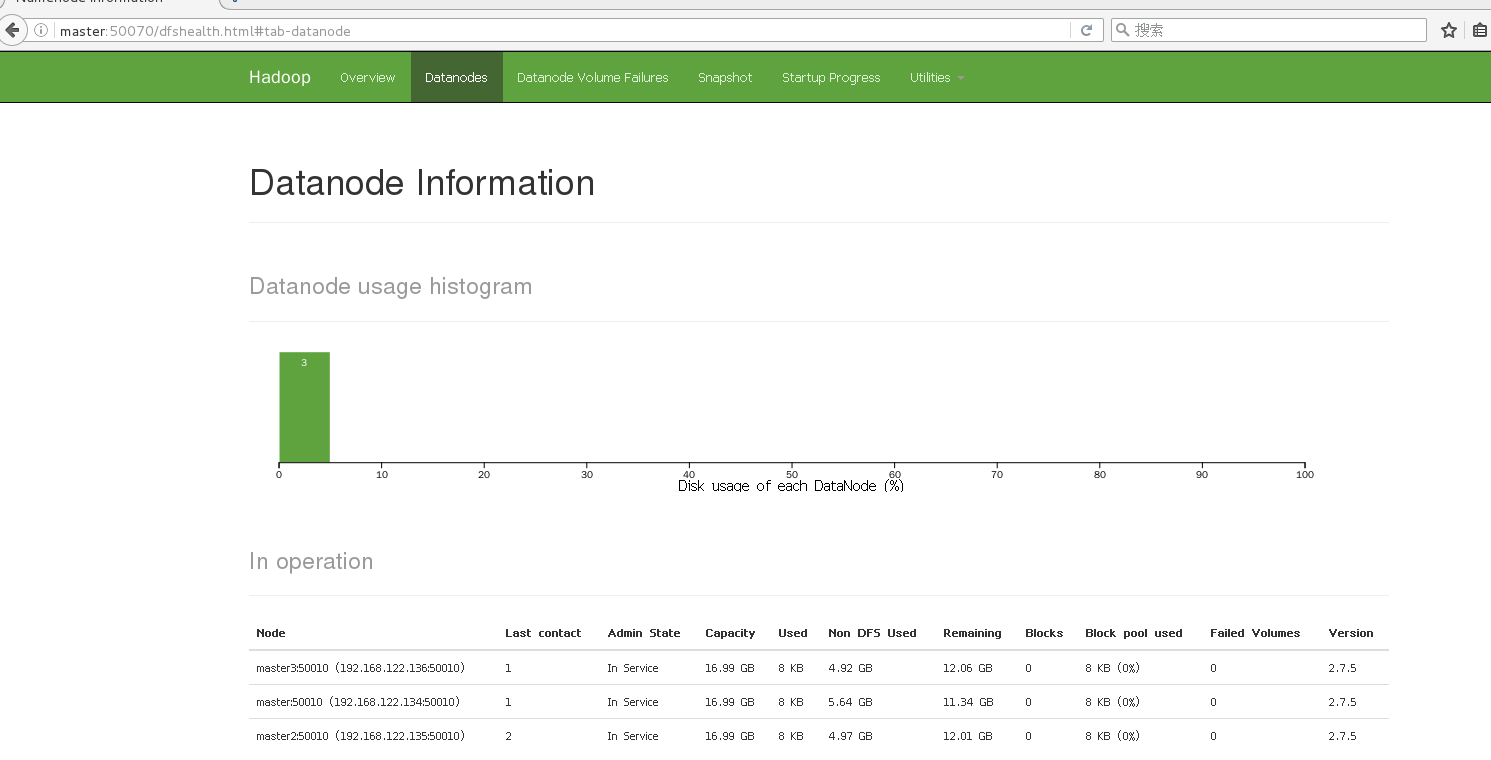
19.stop-dfs.sh关闭集群
四、注意事项
1.format只能进行一次,否则会导致配置数据丢失搭建失败
2.是否正常运行,可以用jps命令查看。
3.如果不正常,可以去看一下其资源存放路径是否生成资源,一般有的话就对了,否则可以重新format一下,在format之前要删除每台机器上生成的/opt/下的hadoop-2.7.5包,在重新format。
注:这里的不正常包含只显示一个结点,以及不显示网页等,都可以尝试这个方法。
注:
- 如有不正确还请见谅。
- 另外,我做了一些关于Spring、Struts、Hibernate的小应用可以帮助理解这些框架,如需代码请访问我的Github:https://github.com/Zxnaruto

