
一、配置zookeeper
- 1.上传zookeeper压缩包,解压
- 2.进入zookeeper解压好的文件夹中,进入conf
- 3.cp zoo_sample.cfg zoo.cfg 复制生成文件zoo.cfg
- 4.修改vim zoo.cfg
datadir=/opt/zookeeper
添加
server.1=changda01:2888:3888
server.2=changda02:2888:3888
server.3=changda03:2888:3888
保存退出 scp传到其他两台机器
scp –r /usr/zookeeper-3.4.6 root@changda02:/usr/
scp –r /usr/zookeeper-3.4.6 root@changda03:/usr/ - 5.到 /opt/下mkdir zookeeper
进入zookeeper 然后创建 vim myid 里面写入1(第二台写入2,第三台写入3)
三台都要去/opt/创建zookeeper和myid,并写入值(vim myid)
保存退出 - 6.配置zookeeper
vim /etc/profile
添加:
ZOOKEEPER_HOME=/usr/zookeeper-3.4.6
PATH=$ZOOKEEPER_HOME/bin:$PATH
export ZOOKEEPER_HOME PATH
然后scp /etc/profile root@changda02:/etc/ scp传到三台
同时重新加载 source /etc/profile 7.zkServer.sh start 每一台
然后zkServer.sh status看是否成功关闭命令:zkServer.sh stop
测试完都先关闭二、集群安装
jdk和hadoop的相关配置可以去看hadoop集群搭建的文档
这里要在上面的基础上修改core-site.xml和hdfs-site.xml配置文件
注:这里是完全修改要删除原先的配置
(1)修改core-site.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25<configuration>
<!-- 指定hdfs的nameservice为myha01 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myha01/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.5/data/hadoopdata/</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>changda01:2181,changda02:2181,changda03:2181</value>
</property>
<!-- hadoop链接zookeeper的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>1000</value>
<description>ms</description>
</property>
</configuration>
(2)修改hdfs-site.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107<configuration>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 配置namenode和datanode的工作目录-数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.7.5/data/hadoopdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-2.7.5/data/hadoopdata/dfs/data</value>
</property>
<!-- 启用webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定hdfs的nameservice为myha01,需要和core-site.xml中的保持一致
dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。例如,如果使用"myha01"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符 -->
<property>
<name>dfs.nameservices</name>
<value>myha01</value>
</property>
<!-- myha01下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.myha01</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myha01.nn1</name>
<value>changda01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.myha01.nn1</name>
<value>changda01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myha01.nn2</name>
<value>changda02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.myha01.nn2</name>
<value>changda02:50070</value>
</property>
<!-- 指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表 该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId journalId推荐使用nameservice,默认端口号是:8485 -->
<property>
<name>dfs.namenode.shared.edits.dir</name> <value>qjournal://changda01:8485;changda02:8485;changda03:8485/myha01</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-2.7.5/data/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.myha01</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-
timeout.ms</name>
<value>60000</value>
</property>
</configuration>
(3)配置好的hadoop-2.7.5 scp给其他两台机器
scp –r /usr/Hadoop-2.7.5 root@changda02:/usr/
scp –r /usr/Hadoop-2.7.5 root@changda03:/usr/
(4)zkServer.sh start 每台都启动
分别启动zookeeper 的journalnode
hadoop-daemon.sh start journalnode
jps查看状态
删除opt/hadoop-2.7.5,三台都删
重新format,在任意一台,选changda01,
hadoop namenode -format
然后将相关文件考到第二个namednode,就是将/opt/hadoop-2.7.5/data/hadoopdata
将其复制到standby的namenode这里指长大02
scp -r hadoopdata root@changda02:/opt/hadoop-2.7.5/data/
(5)格式化zkfc,在第一台机器上就可以
hdfs zkfc –formatZK
(6)启动集群
start-dfs.sh
三、结果显示
启动后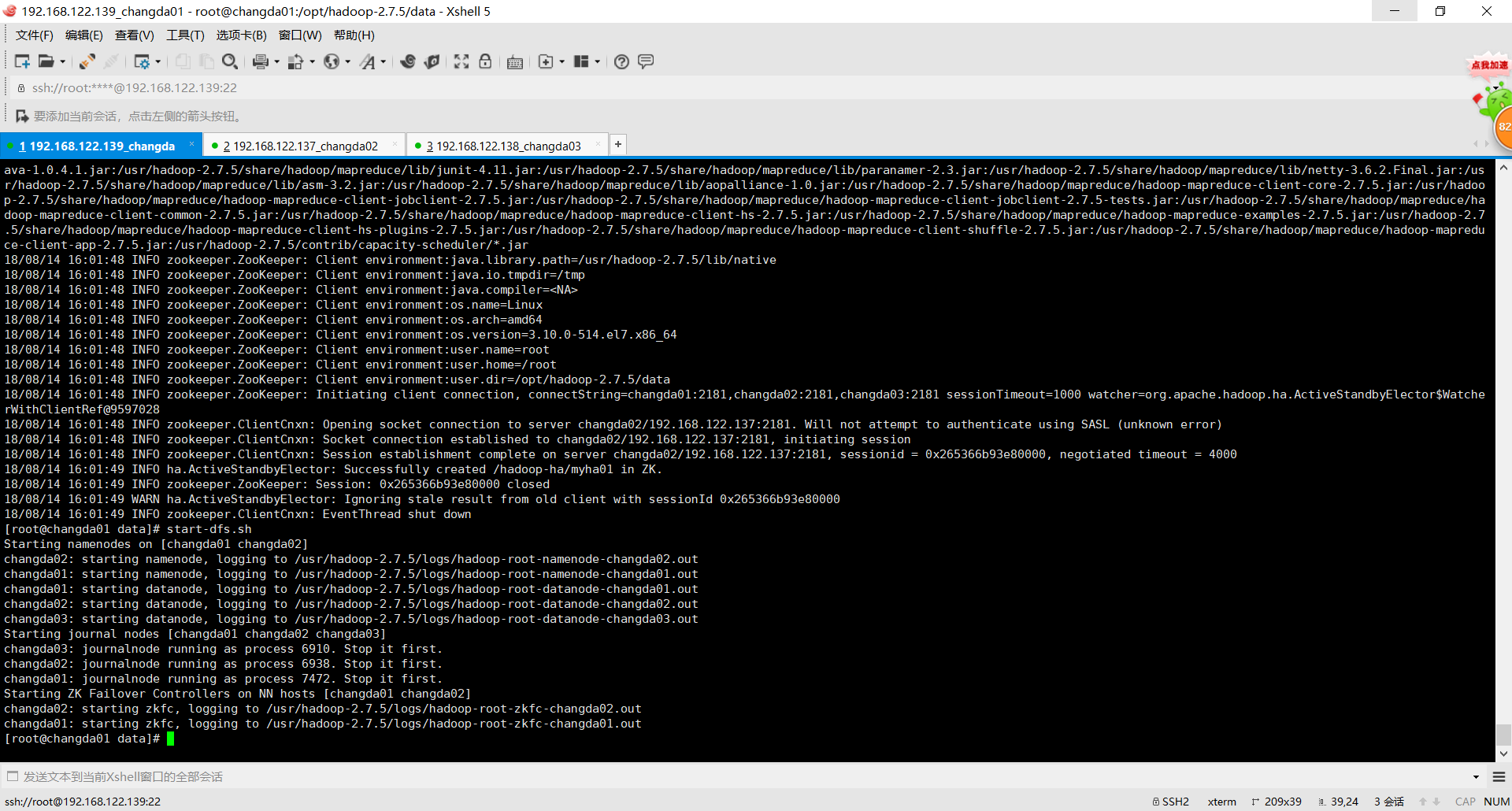
输入url查看效果
有一个standby和一个active。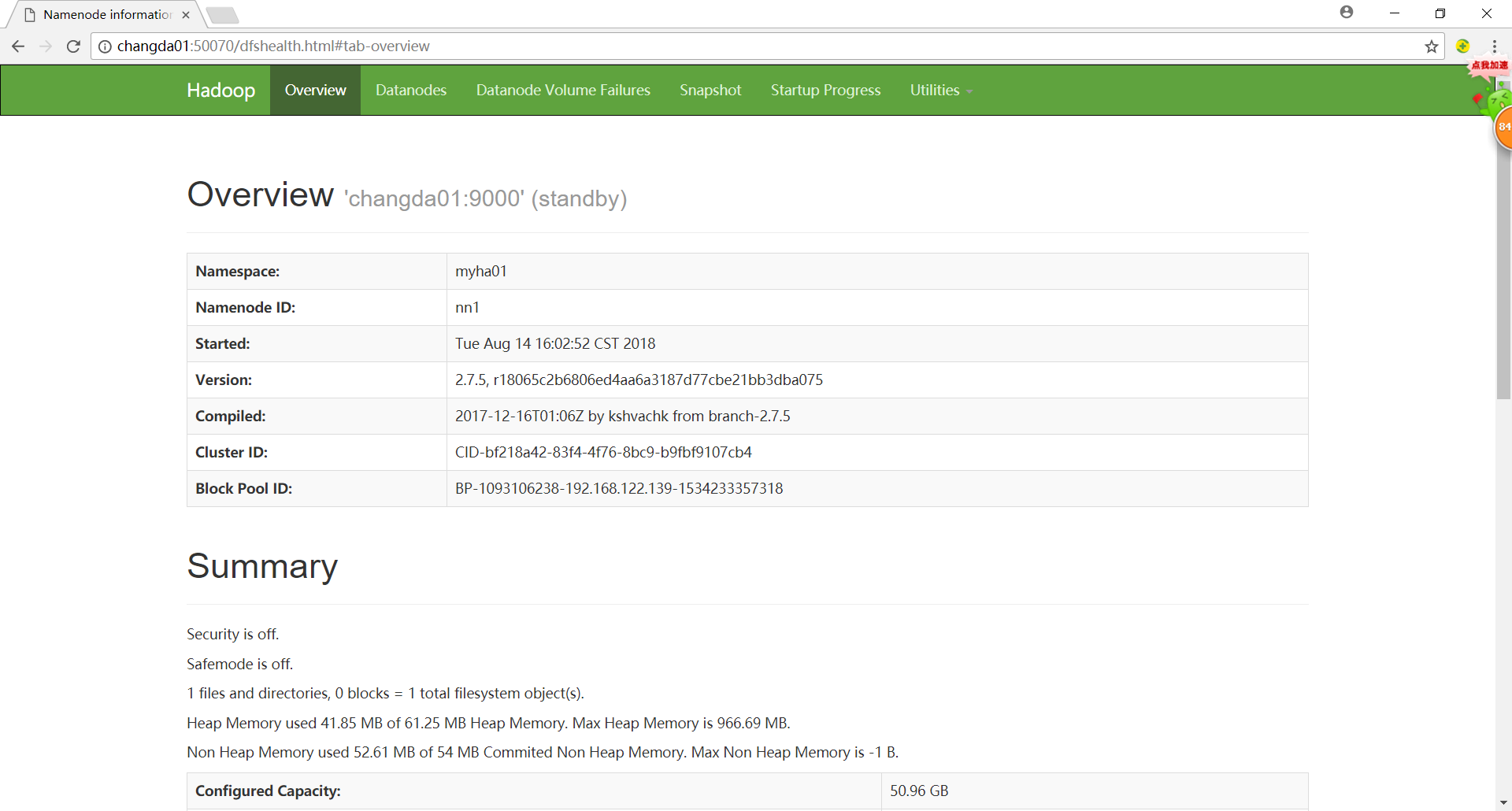
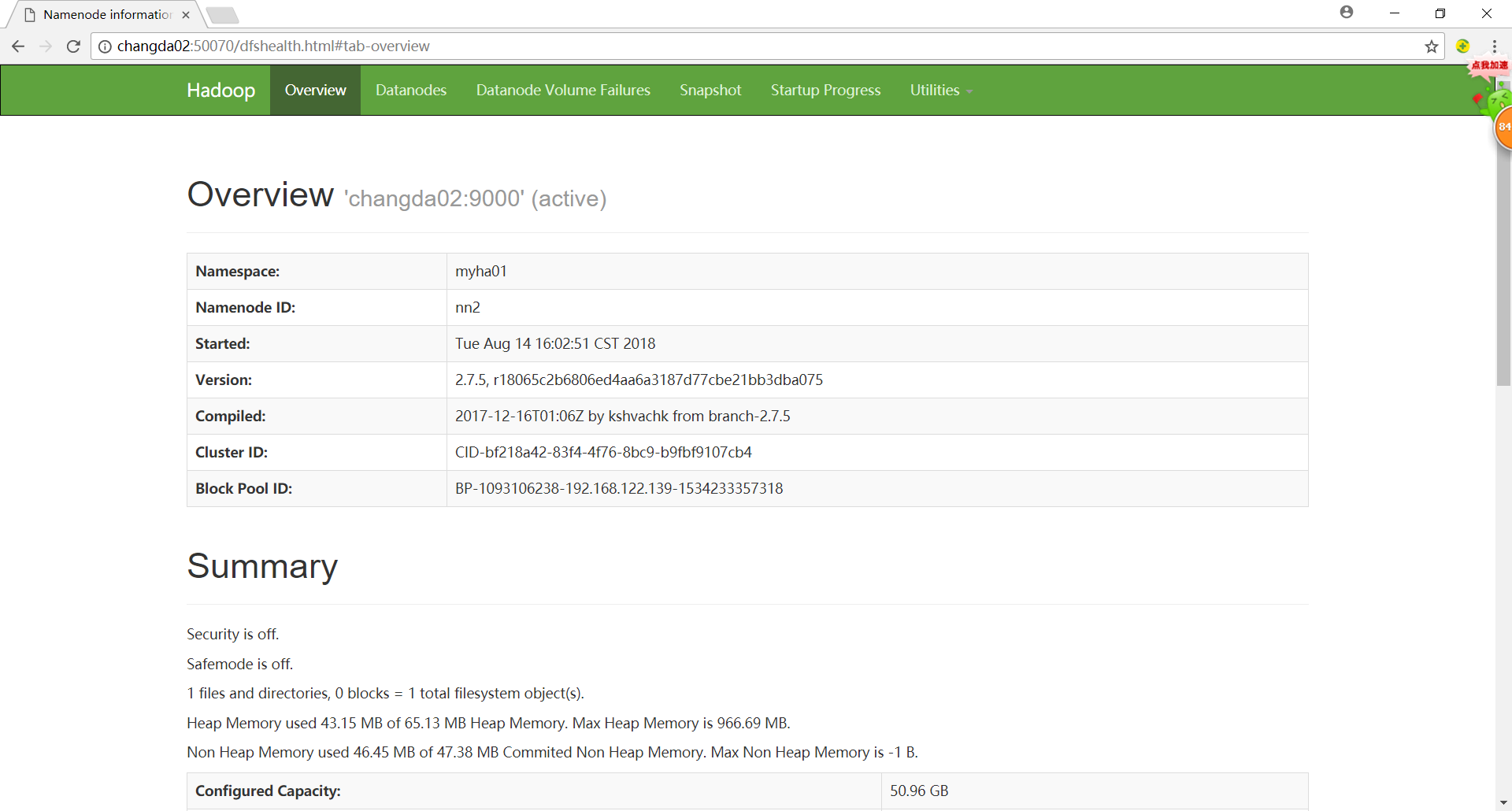
注:
- 如有不正确还请见谅。
- 另外,我做了一些关于Spring、Struts、Hibernate的小应用可以帮助理解这些框架,如需代码请访问我的Github:https://github.com/Zxnaruto

